机器学习处理器
许多行业正在迅速采用人工智能和机器学习(AI/ML)技术来解决许多其他方法难以解决的棘手问题。图像、视频、语音和机器生成数据等数字数据的爆炸式增长,来自无数来源,包括社交媒体、物联网和无处不在的摄像头的视频,推动了分析从数据中提取知识的需求。这些数据分析通常依赖于AI/ML算法,这些算法具有快速解决经典计算机算法无法解决的高维问题的独特能力。
许多AI/ML算法的核心是模式识别,通常作为神经网络实现。AI/ML算法开发人员广泛采用深度卷积神经网络(DNN),因为这些深度网络为重要的图像分类任务提供了最先进的精度。AI/ML算法通常采用矩阵向量数学,每秒需要数万亿次乘法/累加(MAC)运算。执行这些核心AI/ML数学运算需要许多快速乘法器和加法器,通常称为MAC单元。
FPGA作为AI/ML引擎
Achronix的新型真人百家乐系列是专门为应对这些挑战而设计的。真人百家乐架构的各个方面都经过了调整,为AI/ML应用程序创建了一个优化、平衡、大规模并行的计算引擎。每个真人百家乐都有一个大规模并行的可编程计算元件阵列,这些元件被组织成新的机器学习处理器(MLP)块。每个MLP都是一个高度可配置的计算密集型块,最多有32个乘法器,支持4到24位的整数格式和各种浮点模式,包括直接支持Tensorflow的bfloat16格式和块浮点(BFP)格式。
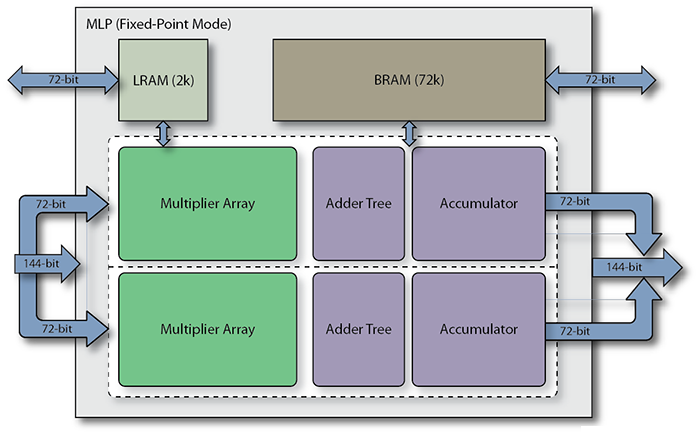
MLP的可编程MAC结合了可分整数MAC和硬浮点MAC。Speedster7t结构中的每个MLP块还包含两个与MAC块紧密耦合的存储器。一个存储器是一个大型双端口72 kb嵌入式SRAM(BRAM72k),另一个是2 kb(LRAM2k)循环缓冲器。可用MLP块的数量因设备而异,但可以达到数千个。
MAC的可分性使其能够最佳地处理AI/ML推理算法越来越多地使用的精度降低的计算,以最大限度地减少内存需求。由于其可分性,随着数字格式精度的降低,MLP可以执行越来越多的计算。
功能丰富、性能最高的操作
MLP提供了一系列功能,包括带可选累加的整数乘法、bfloat16运算、浮点16、浮点24和块浮点16。以下是MLP块可用的功能列表:
- 完全可分整数乘法器/累加器以有效地支持机器学习推理和更传统的应用,如复杂的自适应信号处理。每个MLP支持4x int16、16x int8或32x int4乘法。Speedster7t系列最多支持40960个int8 MAC,在750 MHz下运行时,理论上的最大性能为每秒61.4兆次操作。
- 灵活浮点以大大提高计算中的数值精度。MLP可以重新配置,以支持输入和输出变量的fp15、fp24和bf16数字格式。
- 对块浮点的原生支持在MLP中启用。在块浮点中,单个指数在尾数值块中共享。该方案比定点算法提供了改进的动态范围,性能接近传统浮点算法,但效率明显更高。MLP具有专用电路,可以对块浮点数进行乘法、求和和和累加。
- 最高性能的矩阵乘法MLP利用数据局部性和流,包括集成块RAM以确保最大性能。这些存储器可以独立使用,但对于MLP乘法功能,它们通过不利用FPGA路由资源来确保最高性能和最节能的操作。MLP还包括相邻MLP之间的级联路径,以共享权重或激活数据的存储器和数据,并实现高效的数据结构,如收缩阵列架构。